ETL Pipeline for GenAI
A robust, scalable ETL pipeline designed to process diverse unstructured data sources and prepare them for seamless integration with Generative AI applications, particularly RAG systems
Multi-Format
Data Processing
RAG Ready
AI Integration
Scalable
Architecture
Production
Ready
Powering AI with Clean, Structured Data
Generative AI applications, especially RAG systems, face significant data preprocessing challenges:
- Diverse unstructured data formats (PDFs, Word docs, images, web pages)
- Complex text extraction and cleaning requirements
- Inconsistent data quality and formatting
- Manual preprocessing bottlenecks and scalability issues
A comprehensive pipeline that automates data ingestion, transformation, and preparation for AI applications:
- Multi-format data ingestion (PDF, DOCX, images, websites)
- Intelligent text extraction and preprocessing
- Automated chunking and vector preparation for RAG
- Scalable, production-ready architecture
ETL Pipeline in Action
Visualization of the automated data processing pipeline and GenAI integration workflow
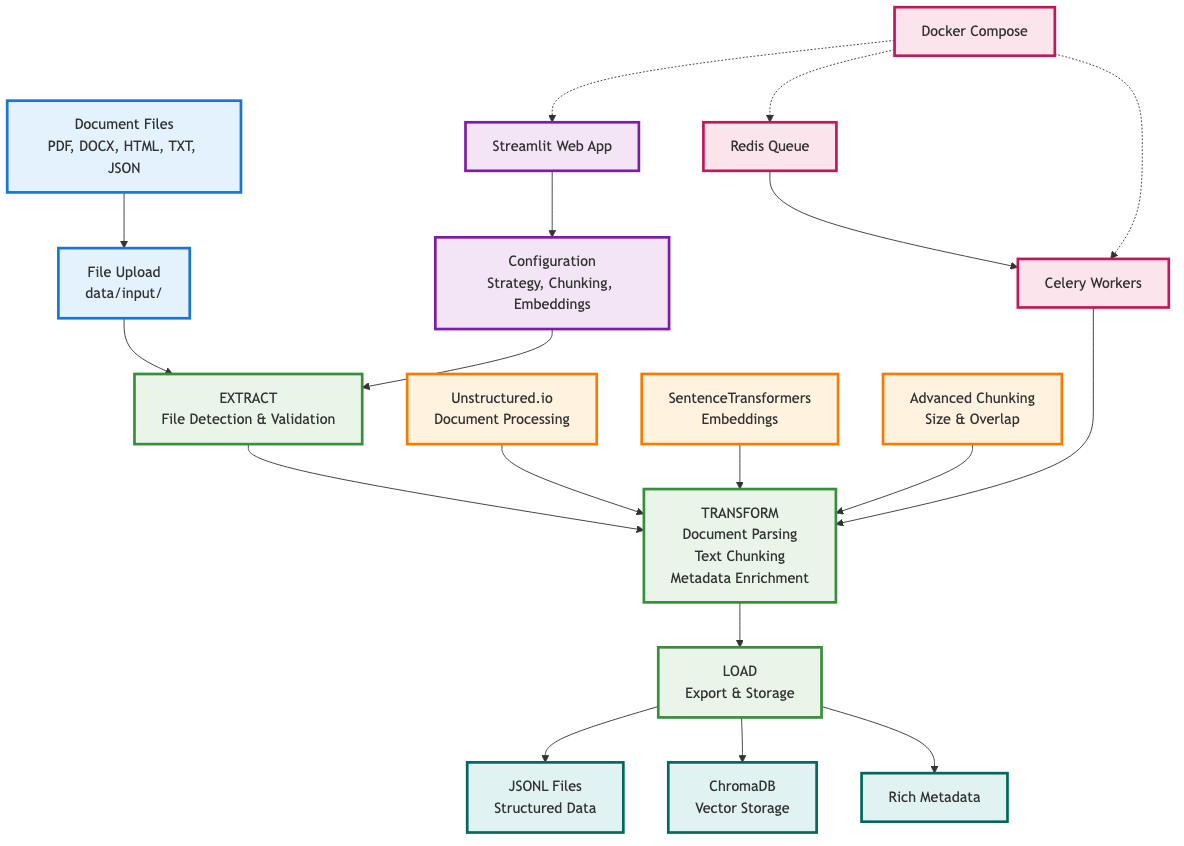
Modern Data Engineering Technologies
Robust Python-based pipeline with workflow orchestration and data manipulation capabilities
Comprehensive text extraction from PDFs, Word documents, web pages, and image-based content
Seamless integration with RAG systems and generative AI applications through proper chunking and embedding
Multi-tier storage architecture supporting structured metadata, document storage, and caching
Containerized deployment with distributed task processing and message queuing for scalability
Comprehensive data quality validation, monitoring, and observability for production environments
Skills Demonstrated & AI Applications
Data preparation for retrieval-augmented generation
Automated document ingestion for corporate AI systems
Intelligent document processing and categorization
Data pipelines for diverse AI application needs